2022-12-03
Twitter を BigQuery と JupyterLab で分析してみた ~ Twitter API v2 ~
Written by: @ekusiadadus

Twitter を BigQuery と JupyterLab で分析してみた ~ Twitter API v2 ~
はじめに
最近、Twitter のデータを分析してみたいと思い、Twitter のデータを取得する方法を調べてみました。 Twitter API というものがあるらしく、Twitter APIを見てみると、結構面白そうだったので、Twitter API に申し込んでみました。 申し込みが通ったので、Twitter API を使って、Twitter のデータを取得してみました。
https://twitter.com/ekusiadadus/status/1586791839469686785
Twitter API で取得したデータを、BigQuery に格納して、JupyterLab で分析してみました。 今回は、Twitter API 部分を紹介します。
Twitter API
Twitter API を使うには、Twitter のアカウントが必要です。 Twitter のアカウントを作成したら、Twitter API を使うために、Twitter に API の申請が必要です。 アプリケーションを作成すると、API キーが発行されます。 API キーを使って、Twitter API を使うことができます。
Twitter API の申請
Twitter API を使うために、Twitter に API の申請が必要です。 この申請をするためには、英語で申請する必要があります。
申請方法は、Twitter APIのページに書いてあります。 申請すると、Twitter からメールが届きます。 自分の場合は、ここで申請理由を結構聞かれて、3 日ほどで申請が通りました。 メールに書いてある URL にアクセスすると、Twitter API を使うための API キーが発行されます。
Twitter API の使い方
Twitter API を使うには、API キーが必要です。 API キーは、Twitter に API の申請をすると、発行されます。
Twitter API を使うには、Twitter APIのページに書いてある通りに、API キーを使って、API を叩く必要があります。
Twitter API には、Playground という、API を叩くためのツールがあります。
Playground で、API を叩くと、API のレスポンスが返ってきます。
curl \
-H "Authorization: Bearer $TOKEN" \
"https://api.twitter.com/2/tweets/search/recent?query=ekusiadadus+-is%3Aretweet&start_time=2022-10-29T00%3A00%3A00Z&end_time=2022-10-30T00%3A00%3A00Z&max_results=10"実行結果:
{
"data": [
{
"edit_history_tweet_ids": ["1586409141777887232"],
"id": "1586409141777887232",
"text": "ハリポタのタリーズ限定のやつ https://t.co/s0jO6JhLt6"
},
{
"edit_history_tweet_ids": ["1586397292164022272"],
"id": "1586397292164022272",
"text": "さすがに、Nextに変えるかぁ https://t.co/10tCmyQBcZ"
},
{
"edit_history_tweet_ids": ["1586396896188198913"],
"id": "1586396896188198913",
"text": "Cloud Flare のこの機能 https://t.co/gZ1HgAV3Q5"
},
{
"edit_history_tweet_ids": ["1586392219438575617"],
"id": "1586392219438575617",
"text": "Twitter API 使えるようになっとった https://t.co/zNJiWXDSTj"
},
{
"edit_history_tweet_ids": ["1586363172692594690"],
"id": "1586363172692594690",
"text": "山手線Netflix になってた https://t.co/araQzC3ovp"
}
],
"meta": {
"newest_id": "1586409141777887232",
"oldest_id": "1586363172692594690",
"result_count": 5
}
}json prettierとか、使いました。
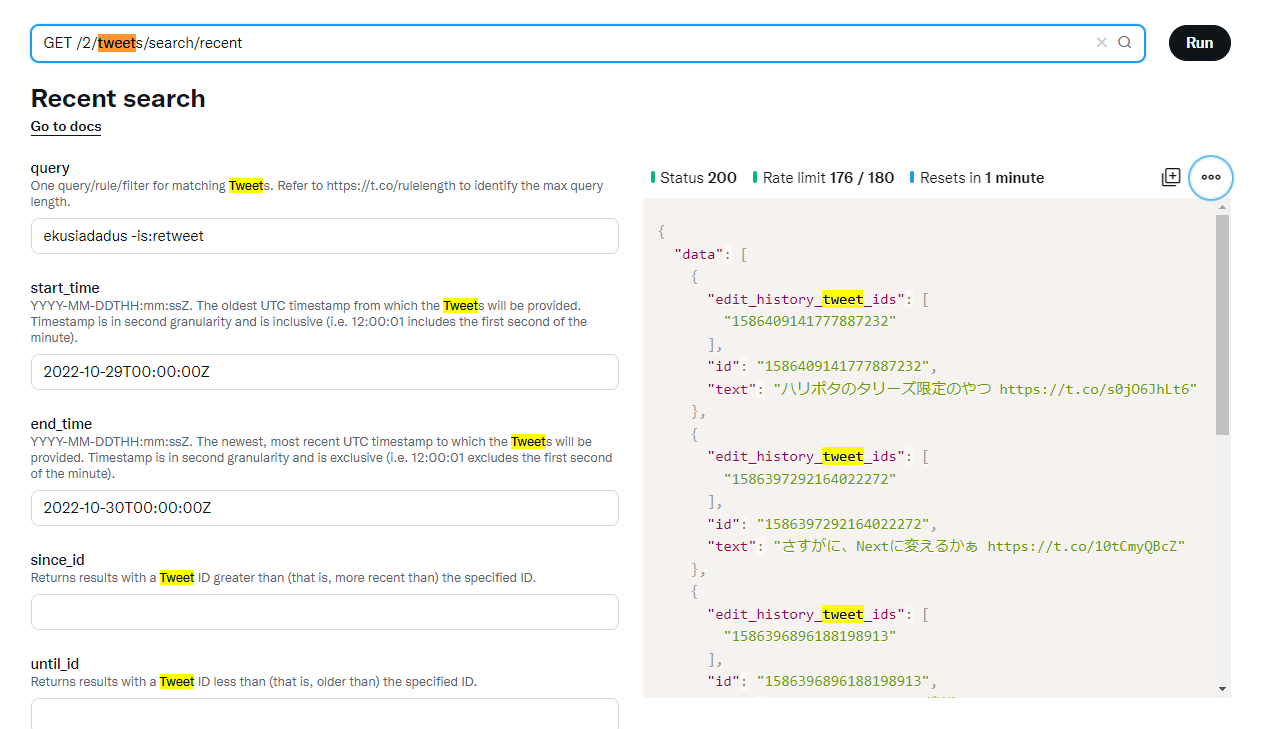
| オプション | 内容 |
|---|---|
| query | 1 つのクエリ/ルール/フィルタがツイートのマッチングに使用されます。最大クエリ長については、https://t.co/rulelength を参照してください。 |
| start_time | ツイートを提供する最も古い UTC タイムスタンプです。タイムスタンプは秒の粒度であり、含みます(つまり、12:00:01 は分の最初の秒を含みます)。 |
| end_time | ツイートを提供する最も新しく、最新の UTC タイムスタンプです。タイムスタンプは秒の粒度であり、除外です(つまり、12:00:01 は分の最初の秒を除外します)。 |
| since_id | 指定した ID よりも新しい(つまり、より新しい)ツイート ID を持つ結果を返します。 |
| until_id | 指定した ID よりも古い(つまり、より古い)ツイート ID を持つ結果を返します。 |
| max_results | リクエストによって返される検索結果の最大数。 |
| next_token | 次の「ページ」の結果を取得するために使用されるパラメータです。パラメータに使用される値は、API によって提供されたレスポンスから直接取得され、変更する必要はありません。 |
| pagination_token | 次の「ページ」の結果を取得するために使用されるパラメータです。パラメータに使用される値は、API によって提供されたレスポンスから直接取得され、変更する必要はありません。 |
| sort_order | 結果を返す順序。 |
| tweet.fields | 表示するツイートフィールドのカンマ区切りリスト。 |
| expansions | 拡張するカンマ区切りリスト。 |
| media.fields | 表示するメディアフィールドのカンマ区切りリスト。 |
| poll.fields | 表示するポールフィールドのカンマ区切りリスト。 |
| user.fields | 表示するユーザーフィールドのカンマ区切りリスト。 |
| place.fields | 表示する場所フィールドのカンマ区切りリスト。 |
上のように、結構詳細にオプションを指定することができます。
ツイートのいいねの数
例えば、あるツイートのいいねの数を取得するには、次のようにします。
curl \
-H "Authorization: Bearer $TOKEN" \
"https://api.twitter.com/2/tweets/1551088040285638657/liking_users?max_results=3&user.fields=public_metrics&expansions=pinned_tweet_id&tweet.fields=context_annotations"{
"data": [
{
"id": "3913044494",
"name": "【Twitterアカウント名】",
"username": "【Twitterユーザー名】",
"public_metrics": {
"followers_count": 8839,
"following_count": 8948,
"tweet_count": 503,
"listed_count": 2
}
},
{
"id": "1488248439272271872",
"pinned_tweet_id": "1576352361819217920",
"name": "【Twitterアカウント名】",
"username": "【Twitterユーザー名】",
"public_metrics": {
"followers_count": 1647,
"following_count": 4922,
"tweet_count": 1477,
"listed_count": 28
}
},
{
"id": "1474657817424707584",
"pinned_tweet_id": "1546867778363469824",
"name": "【Twitterアカウント名】",
"username": "【Twitterユーザー名】",
"public_metrics": {
"followers_count": 788,
"following_count": 719,
"tweet_count": 2557,
"listed_count": 0
}
}
],
"includes": {
"tweets": [
{
"text": "「この道を行けばどうなるものか危ぶむことなかれ 危ぶめば道はなし 踏み出せばその一歩が道となる」\n\n道を作りに来ないか?✨\n\n#ホスト #RT \n#ホストル求人 \n#いいねした人全員フォローする \n#メンコン \n#いいね返し\n#自撮り界隈の人と繋がりたい\n#猪木さんありがとう https://t.co/juGwGlQHcQ",
"edit_history_tweet_ids": ["1576352361819217920"],
"id": "1576352361819217920"
}
]
},
"errors": [
{
"value": "1546867778363469824",
"detail": "Could not find tweet with pinned_tweet_id: [1546867778363469824].",
"title": "Not Found Error",
"resource_type": "tweet",
"parameter": "pinned_tweet_id",
"resource_id": "1546867778363469824",
"type": "https://api.twitter.com/2/problems/resource-not-found"
}
],
"meta": {
"result_count": 3,
"next_token": "7140dibdnow9c7btw481sasymr2mohx4dyy8mdswxdz5l"
}
}ツイートにいいねした人の、ユーザー情報やピン止めしているツイートの情報が取得できます。

Twitter API v2 でデータを取得する
Twitter API でデータを取得するには、Twitter API のライブラリを使います。 今回は、Python で、Twitter API を使うためのライブラリを使って、データを取得しました。 他にも、様々な言語にライブラリが対応しています。
https://developer.twitter.com/en/docs/twitter-api/tools-and-libraries/v2
今回は、Python で、あるキーワードを含むツイートを取得するプログラムを作成しました。
import requests
import os
import urllib
import json
import datetime
from google.cloud import bigquery
bearer_token = os.environ['BEARER_TOKEN']
headers = {"Authorization": "Bearer {}".format(bearer_token)}
def create_url():
now = datetime.datetime.now(
datetime.timezone.utc) - datetime.timedelta(minutes=3)
start = now - datetime.timedelta(days=1)
end = now
start = '{:%Y-%m-%dT%H:%M:%SZ}'.format(start)
end = '{:%Y-%m-%dT%H:%M:%SZ}'.format(end)
# remove retweet
query = urllib.parse.quote("Go言語")
tweet_fields = "tweet.fields=author_id,created_at,entities,geo,id,in_reply_to_user_id,lang,possibly_sensitive,referenced_tweets,source,text,withheld"
url = "https://api.twitter.com/2/tweets/search/recent?query={}+-is%3Aretweet&{}&start_time={}&end_time={}".format(
query, tweet_fields, start, end)
return url
def get_params():
return {"max_results": 10}
def connect_to_endpoint(url, params):
response = requests.request("GET", url, headers=headers, params=params)
print(response.status_code)
if response.status_code != 200:
raise Exception(response.status_code, response.text)
return response.json()
def main():
url = create_url()
params = get_params()
json_response = connect_to_endpoint(url, params)
with open('data.json', 'w') as outfile:
json.dump(json_response, outfile)
# convert_json_to_ndjson()
# insert_into_bigquery()
if __name__ == "__main__":
main()実際に動かすと、data.json というファイルが作成されます。
{
"data": [
{
"possibly_sensitive": false,
"lang": "ja",
"source": "Twitter Web App",
"created_at": "2022-10-30T15:16:28.000Z",
"author_id": "1299285051436273664",
"entities": {
"urls": [
{
"start": 33,
"end": 56,
"url": "https://t.co/cjeLSG0JaW",
"expanded_url": "https://twitter.com/ekusiadadus/status/1586738814474539008/photo/1",
"display_url": "pic.twitter.com/cjeLSG0JaW",
"media_key": "3_1586738687353634816"
}
]
},
"edit_history_tweet_ids": ["1586738814474539008"],
"id": "1586738814474539008",
"text": "気が付かなかったけれど、GitHubがハロウィン🎃\nになっていた https://t.co/cjeLSG0JaW"
},
{
"possibly_sensitive": false,
"lang": "ja",
"source": "Twitter Web App",
"created_at": "2022-10-30T07:46:10.000Z",
"author_id": "1299285051436273664",
"entities": {
"urls": [
{
"start": 14,
"end": 37,
"url": "https://t.co/Hh9UB9dVyj",
"expanded_url": "https://twitter.com/ekusiadadus/status/1586625496015466496/photo/1",
"display_url": "pic.twitter.com/Hh9UB9dVyj",
"media_key": "3_1586625454777040896"
}
]
},
"edit_history_tweet_ids": ["1586625496015466496"],
"id": "1586625496015466496",
"text": "トレンドってすごいんだなぁ https://t.co/Hh9UB9dVyj"
},
{
"possibly_sensitive": false,
"lang": "zxx",
"source": "Twitter Web App",
"created_at": "2022-10-30T07:45:24.000Z",
"author_id": "1299285051436273664",
"entities": {
"urls": [
{
"start": 0,
"end": 23,
"url": "https://t.co/X3S49JX8cN",
"expanded_url": "https://twitter.com/ekusiadadus/status/1586625301068492801/photo/1",
"display_url": "pic.twitter.com/X3S49JX8cN",
"media_key": "3_1586625294277890048"
}
]
},
"edit_history_tweet_ids": ["1586625301068492801"],
"id": "1586625301068492801",
"text": "https://t.co/X3S49JX8cN"
},
{
"possibly_sensitive": false,
"lang": "ja",
"source": "Twitter Web App",
"created_at": "2022-10-30T07:43:37.000Z",
"author_id": "1299285051436273664",
"entities": {
"urls": [
{
"start": 39,
"end": 62,
"url": "https://t.co/niBE1dVLlL",
"expanded_url": "https://twitter.com/ekusiadadus/status/1586624851254513664/photo/1",
"display_url": "pic.twitter.com/niBE1dVLlL",
"media_key": "3_1586624768077225984"
}
]
},
"edit_history_tweet_ids": ["1586624851254513664"],
"id": "1586624851254513664",
"text": "やっぱり、ハロウィンとか特別な日だと全日との検索上位の差分がおおきくなるのか https://t.co/niBE1dVLlL"
},
{
"possibly_sensitive": false,
"lang": "ja",
"source": "Twitter Web App",
"created_at": "2022-10-30T07:23:11.000Z",
"author_id": "1299285051436273664",
"entities": {
"urls": [
{
"start": 32,
"end": 55,
"url": "https://t.co/wbbWezaHhg",
"expanded_url": "https://twitter.com/ekusiadadus/status/1586619708031193088/photo/1",
"display_url": "pic.twitter.com/wbbWezaHhg",
"media_key": "3_1586619586509561857"
}
]
},
"edit_history_tweet_ids": ["1586619708031193088"],
"id": "1586619708031193088",
"text": "ひさびさにgcp上で、NoteBook立てたけど大分変っていた https://t.co/wbbWezaHhg"
}
],
"meta": {
"newest_id": "1586738814474539008",
"oldest_id": "1586619708031193088",
"result_count": 5
}
}